Ako nás (ne)limituje Azure Cognitive Search
V naších systémoch sme sa rozhodli využiť Azure Cognitive Search (ACS) na fulltextové vyhľadávanie a zložitejšie fitrovanie v dátach. Nejedná sa o statické dáta, ale o štandardné aplikačné dáta ekonomických systémov (faktúry, predfaktúry, cenové ponuky, skladové karty, …). Očakávame, že ACS bude dokumenty indexovať takmer v reálnom čase.
Indexér, ktorý môžete pridať k Vášmu indexu má minimálny schedule time 5 minút, čo nám nevyhovuje. Preto sme sa rozhodli, že využijeme AZURE Function naplánovanú na každú sekundu. Táto funkcia vytiahne všetky zmenené dáta v danej databáze a tie pošle v dávke zaindexovať do ACS.
Vzniká tu otázka, bude to ACS stíhať? Dokáže indexovať dokumenty v požadovanom čase? Nepotrebujeme naozaj realtime, ale očakávame, že dokumenty budú pre používateľa dostupné v jednotkách sekúnd.
Ako si to overiť?
Za štandardných okolností by sme na danú vec napísali load test (Na load testy využívame JMeter. Snáď sa mi aj o ňom niekedy podarí napísať nejaký článok.). Toto ale nie je štandardná situácia. Api pomocou ktorého posielate dáta na indexovanie vám vráti odpoveď okamžite ako príjme dáta. To, kedy sú dáta reálne zaindexované, je z vášho pohľadu nedeterministická operácia a o jej (ne)úspešnosti nie ste notifikovaný. Otázka teda je, ako? Môžete síce opakovane volať dotazy na ACS s nejakým filtrom na základe ktorého zistíte či váš záznam sa tam už nachádza. Ale takýmto aktívnym čakaním výrazne zvýšite záťaž vášho ACS a tým pádom ovplyvníte aj samotné indexovanie.
Viem o čom hovorím. Snažili sme sa niečo podobné robiť, aby sme vedeli notifikovať frontend o tom, že dáta boli zaindexované. Dostali sme sa až do stavu, že nás začal ACS throttlovať 🙄. Nerobte to 😉!
Myšlienku mi vnúkol kolega (diki Gabo 😉). “Skúsme sledovať rozdiel medzi počtom odoslaných dokumentov a počtom aktuálne zaindexovaných dokumentov.” Na základe toho by sme mali byť schopný odhadnúť či ACS dokáže takmer v reálnom čase indexovať naše dokumenty.
A z toho vznikol nasledovný scenár.
Test case 1
Novo vytvorený ACS (1 Replication x 1 Partition). V cykle budem generovať náhodné objednávky pomocou AutoBoqus aj s položkami (veľmi podobný index ako v jednom z naších modulov / mikroslužieb) V rámci jednej iterácie vygenerujem od 20 do 300 dokumentov a tie pošlem ako batch zaindexovať do ACS. Následne sekundu počkám. (v princípe podobne to robíme aj v našom systéme, kde naša indexovacia Azure funkcia po každej sekunde odošle dávku zmenených dát)
20 až 300 je odhadovaný počet dokumentov, ktoré u nás vzniknú za jednu sekundu.
Po tejto sekunde zistím aktuálny počet dokumentov v ACS (pomocou tohto Api).
Celkový počet iterácií je 1 000.
Výsledky
Pre nás to dopadlo pozitívne. 82% iterácií dopadlo tak, že po sekundovom čakaní boli všetky dáta zaindexované.
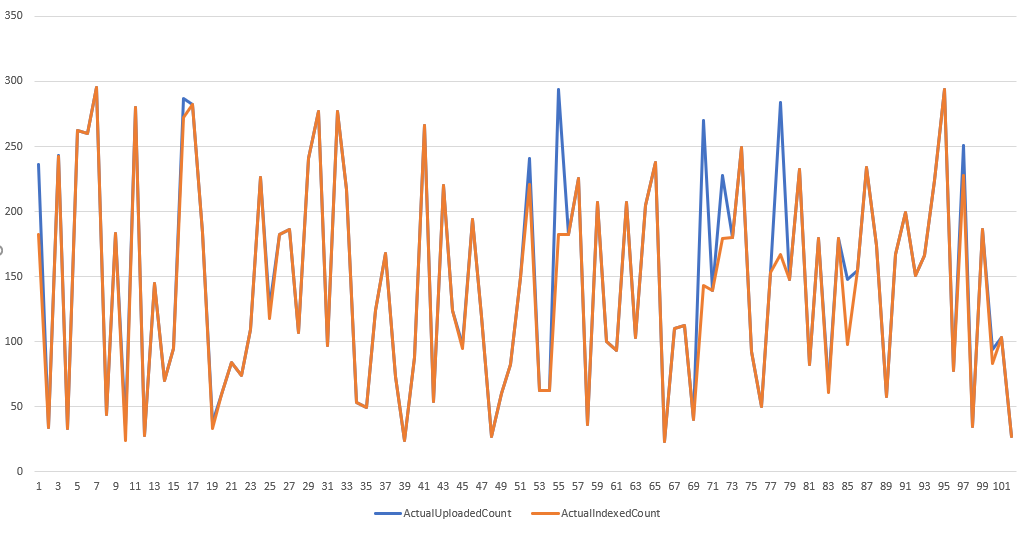
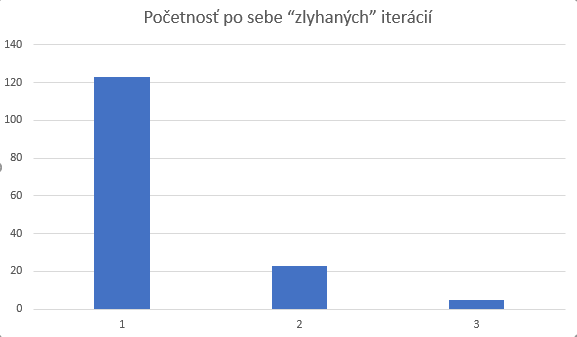
To, že sa občas v niektorej z iterácií nezaindexujú všetky dáta nám neprekáža. Dôležité pre nás je, aby nebolo priveľa po sebe idúcich iterácií v ktorých neboli zaindexované nejaké dáta. To by mohlo naznačovať, že ACS nestíha indexovať a zaindexovanie dokumentu trvá niekoľko sekúnd. (ale taktiež nemuselo, záležalo by v tom prípade od počtu nezaindexovaných dát)
Preto sledujeme aj početnosť po sebe idúcich iterácií, v ktorých neboli zaindexované všetky dokumenty.
Celkovo bolo zaindexovaných 161 000 dokumentov. Čo už nie je najmenší index. Každopádne podľa priebehu to vyzerá tak, že aktuálny počet dokumentov v indexe nemá vplyv na rýchlosť indexovania ďalších dokumentov.
Test case 2
Ok, prvý test dopadol dobre. Pre nás z toho vyplýva, že náš systém zvládne očakávanú záťaž. Keď však máme nachystaný spôsob ako odhadnúť priebeh indexovania v ACS, tak prečo nespraviť rovno aj stress test 😃?
Rovnaký scenár ako v prvom prípade, ale v každej iterácií budeme generovať 20 až 600 dokumentov.
Výsledky
Podľa mojich očakávaní je to už o poznanie horšie. Len 40% iterácií dopadlo, tak že všetky dáta boli zaindexované.
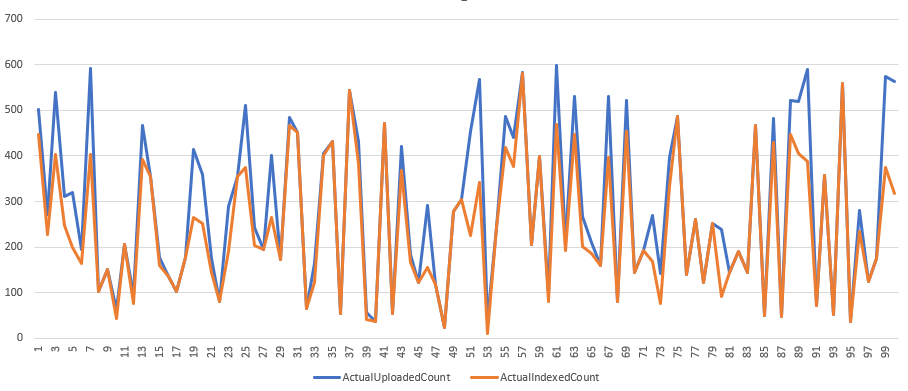
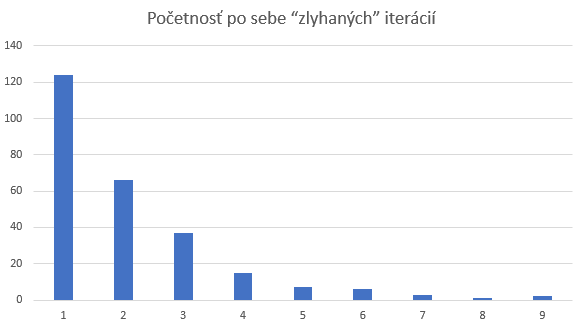
Test case 3
Predchádzajúce výsledky by sme chceli vylepšiť. Na rýchlosť indexovania má mať vplyv počet partícií. Preto zvýšime počet partícií v ACS na 2. (ostatné parametre sú rovnaké)
Výsledky
Opäť sa potvrdili očakávania a zvýšenie počtu partícií vrátilo čísla do “normálu”.
V 80% bol počet zaindexovaných dokumentov zhodný s počtom odoslaných.
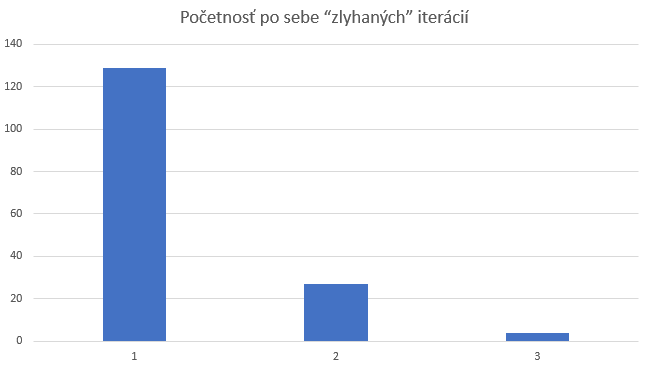
Vyhodnotenie
Rád by som sa vyhol všeobecným záverom, pretože tu chýbajú veci, ktoré môžu ovplyvniť výsledky.
- Počas indexovania nikto nevyhľadáva
- Dokumenty sa len pridávajú, nerobí sa update dokumentov
- Dáta sú generované. Síce sú generované na základe určitých konvencií, ale sú výrazne rozmanitejšie ako v realite. A keďže ACS využíva invertovaný index, tak to má vplyv minimálne na veľkosť indexu
Nás to však presvedčilo, že ACS vyhovuje naším požiadavkám.
Celý load test je zverejnený v repe Sample.AzureSearchLoadTests. Je tam aj pripravaná Terraform definícia infraštruktúry, takže si to môžete sami vyskúšať.